
Would you like to know what canonical tags are and how you can use them to avoid the dreaded problems with duplicate content?
Canonical tags are nothing new, they have been around since 2009. Google, Microsoft, and Yahoo joined forces to create them.
The goal?
Providing a way for website owners to quickly and easily resolve duplicate content problems on websites.
Do they work?
Yes, perfect … but only if you know how to use them!
What is a Canonical Tag?
A canonical tag is an excerpt from HTML code that defines the major version for duplicate, almost duplicate, and similar pages.
In other words, if you have the same or similar content available at different URLs, you can use canonical’s tags to determine which version is the major version and should therefore be indexed.
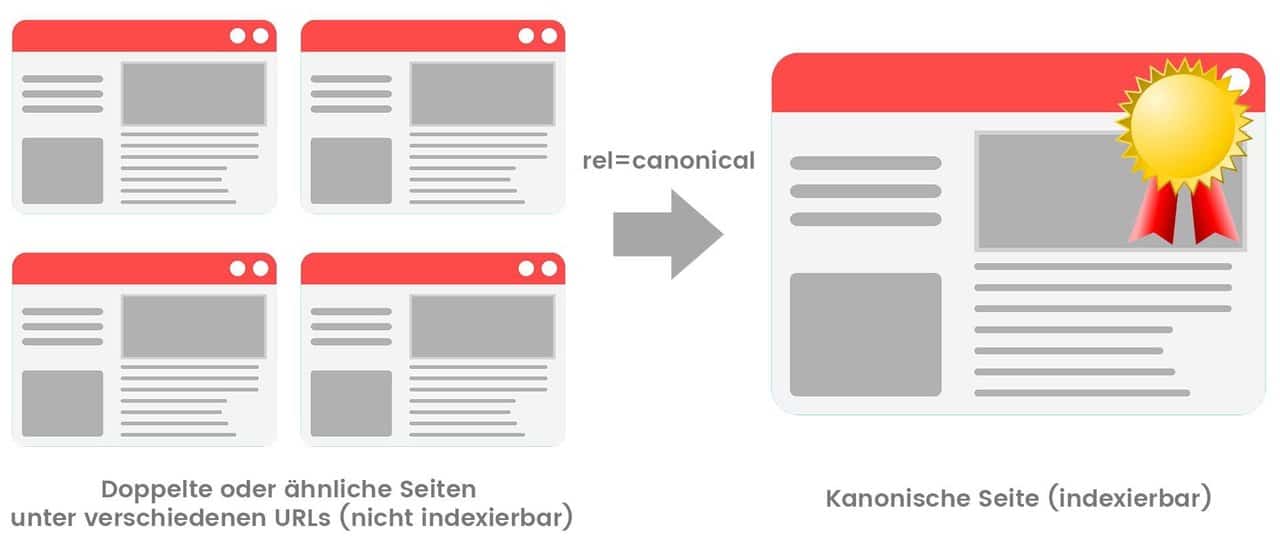
What does a canonical tag look like?
Canonical tags use a simple and consistent syntax and are placed within the <head> area of a website:
<link rel="canonical" href="https://beispiel.de/seite-1/" />
This means every part of the code in plain language:
1. link rel = ”canonical” : The link in this tag is the main version (canonical version) of this page.
2. href = ”https://beispiel.de/seite-1/” : The canonical version can be found under this URL.
Why are Canonical Tags important to SEO?
Google doesn’t like duplicate content. It makes it harder for them to choose:
- Which version of a page to index (they will only index one!)
- Which version of a page should be found for relevant searches
- Whether you want to merge the “Link Equity” on one page or split it into several versions
Too much duplicate content can also affect your “crawl budget”. This means that Google can end up wasting time searching through multiple versions of the same page instead of discovering other important content on your site.
The truth about the crawl budget
Forcing Google to waste time crawling duplicate content is, of course, something that should be avoided whenever possible. However, Google states that it won’t be a problem for most websites.
“When new pages tend to be crawled the same day they are published, the crawl budget is not something webmasters need to focus on. Likewise, if a website has fewer than a few thousand URLs, most of the time it will be crawled efficiently. “
Canonical tags solve all of these problems. They allow you to tell Google which version of a page to index and list, and where to merge the “link equity”.
If you don’t include a canonical URL , Google will take matters into their own hands :
“If you don’t provide a canonical URL, we’ll try to determine the most appropriate version or URL.”
Relying on Google here is not a good idea. Google might pick a version of your page that you don’t really want canonical.
Important NOTE
Google states that they usually accept the canonical url you set, but not always.
“Even if you explicitly specify a canonical page, Google may choose for a variety of reasons, such as: B. due to the performance or the content, a different canonical side. “
Using canonical tag best practices will help reduce the risk of Google recognizing an unwanted version of the page as canonical.
But I don’t have duplicate content, do I?
Since you have likely not published the same posts and pages multiple times, it is easy to assume that your website does not have duplicate content.
But search engines crawl URLs, not web pages.
This means that Google see example.de/product and example.de/product?color=red as unique pages, even though they are the same website with identical or similar content.
These are known as parameterized URLs and are a common cause of duplicate content, especially on ecommerce sites with faceted / filtered navigation. For example, when you filter products by color or size, a parameter like ? Color = blue or ? Size = xl is often added to the URL.
In the eyes of Google, these are all separate pages, even if the content differs only slightly.
But it’s not just ecommerce sites that fall victim to duplicate content.
Here are other common causes of duplicate content that are common to all types of websites:
- Parameterized URLs for search parameters (e.g. example.de?q=suchwort)
- Parameterized URLs for session IDs (e.g. https://beispiel.de?sessionid=3)
- Separate printable versions of pages (e.g. example.de/seite and example.de/druck/seite)
- Unique URLs for articles in different categories (e.g. example.de/services/seo/ and example.de/specials/seo/)
- Pages for different device types (e.g. example.de and m.beispiel.de)
- AMP and non-AMP versions of a page (e.g. example.de/page and amp.example / page)
- The same content for the variants of non-www / www and non-https / https (e.g. https://beispiel.de and https://www.beispiel.de)
Proper use of canonical tags is critical in these situations.
Additionally, cross-domain duplicate content issues are also an issue. If you are distributing content (e.g., if a newspaper wants to publish your content verbatim on their website) then you should ask them to provide a canonical link to the original.
This way it is possible to get the traffic from this publication while minimizing the risk of Google indexing the wrong url.
Note : Some websites may refuse to add a canonical link. In this case, it’s up to you whether you want to take the risk. If so, it’s worth keeping an eye on the syndicated page to make sure it doesn’t rank above the original.
Basics for using canonical tags
Canonicals are easy to implement. We’re going to discuss four different ways in which we can do this. But no matter which method you choose, there are five golden rules that you should always remember.
Rule 1: Use absolute URLs
Google’s John Mueller explains that the best practice is not to use relative paths with the rel = ”canonical” link element:
“You can use both. However, I recommend using absolute URLs to make sure they are interpreted correctly. “
Hence, you should use the following structure:
< link rel="canonical" href="https://beispiel.de/beispielseite/" />
In contrast to this one:
< link rel="canonical" href="/beispielseite/" />
Rule 2: Use lowercase URLs
Since Google can treat uppercase and lowercase URLs as two different URLs, you should first make sure that lowercase letters are enforced on your server and then use lowercase URLs for your canonical tags.
Rule 3: Use the correct domain version (HTTPS vs. HTTP)
If you’ve switched to SSL, make sure you don’t include non-SSL (i.e. HTTP) URLs in your canonical tags. This can lead to misunderstandings and unexpected results.
If you’re on a secure domain, make sure you’re using the following version of your URL:
< link rel="canonical" href="https://beispiel.de/beispielseite/" />
In contrast to:
< link rel="canonical" href="http://beispiel.de/beispielseite/" />
Note : If you’re not using HTTPS, the opposite is true.
Rule 4: Use self-referencing canonical tags
Google’s John Mueller says that while not mandatory, self-referencing canonical tags are recommended :
“I recommend using a self-referencing canonical tag as it really makes it clear to us which page you want to index, or what the URL should be when it’s indexed.
Even if you have a page, sometimes there are different flavors of the URL that can pull that page up. For example with parameters at the end, maybe with capital letters or www and not-www. All of these things can be cleaned up with a canonical tag. “
In case you’re not sure how a self-referential canonical works, it’s basically a canonical tag on a page that points to itself.
For example, if the URL were https://examplepage.de/examplepage , then a self-referencing canonical on this page would be:
< link rel="canonical" href="https://beispiel.de/beispielseite" />
Most modern and popular CMS automatically add self-referencing URLs. If you are using a custom CMS you will need to have your developer hardcode for it.
Rule 5: Use one canonical day per page
If the page has multiple canonical tags then Google will ignore them both.
Here is a translated excerpt from Google’s Webmaster Central Blog :
“In the case of multiple declarations of rel = canonical, Google will probably ignore all rel = canonical references.”
How to use canonical tags
There are four ways to determine canonical URLs:
- HTML tag (rel = canonical)
- HTTP headers
- Sitemap
- 301 redirect
You can find the advantages and disadvantages of each method in the official description from Google .
1. Create canonicals with rel = ”canonical” HTML tags
Using a rel = canonical tag is the easiest and most obvious way to specify a canonical URL.
Just add the following code in the <head> area on each duplicate page:
< link rel="canonical" href="https://beispiel.de/kanonische-seite/" />
example
Let’s say you have an ecommerce website that sells t-shirts. You want https://deinshop.de/tshirts/schwarze-tshirts/ to be the canonical URL, even if the content of this page is accessible via other URLs (e.g. https://deinshop.de/angebote/schwarze-tshirts/ ) is.
Just add the following canonical tag to all duplicate pages:
<link rel="canonical" href="https://deinshop.de/tshirts/schwarze-tshirts/" />
Note : If you’re using a CMS, you don’t have to mess with the code on your page.
There is an easier way.
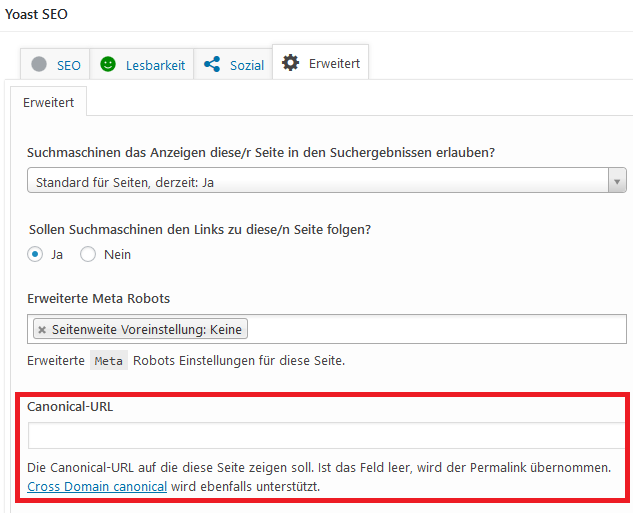
Use canonical tags in WordPress
Install Yoast SEO and the self-referencing canonical tags will be added automatically. To set custom canonicals, use the “Advanced” section in any post or page.
Use canonical tags with Shopify
Shopify adds self-referencing canonical URLs for products and blog posts by default. To set custom canonical URLs, you’ll need to edit the template (.liquid) files directly.
Use canonical tags with Squarespace
Squarespace also adds self-referencing URLs by default. But, as with Shopify, if you want to add a custom canonical URL, you’ll have to edit the code right away.
2. Use canonicals in HTTP headers
For documents such as PDFs, there is no way to set canonical tags in the page header because there is no <head> area. In such cases you have to use HTTP headers to set canonicals.
Example:
HTTP / 1.1 200 OK Content-Type: application / pdf Link: <https://seorankking.de/blog/canonical-tags/>; rel = "canonical"
3. Insert canonicals in sitemaps
Google explains that non-canonical pages should not be included in sitemaps. Only canonical URLs should be listed. This is because Google considers the pages listed in a sitemap to be suggested canonicals.
However, Google will not always read the URLs in the sitemap as canonical URLs:
“We don’t guarantee we’ll make the sitemap URLs canonical, but sitemaps make it easy to set canonical pages for a large website. They are also useful for telling Google which pages on your website are most important. “
4. Determine canonicals with 301 redirects
Use 301 redirects if you want to redirect traffic from a duplicate URL to the canonical version.
example
Assuming your page can be reached under these URLs:
- example.de
- example.de/index.php
- example.de/home
Select your canonical url and redirect the other urls there.
You should do the same for HTTPS / HTTP and www / non-www versions of your website.
The canonical version of seorankking.de is, for example, the HTTPS, non-www-URL (short: https://seorankking.de ).
All of the following urls will be redirected there:
- https://seorankking.de
- https://www.seorankking.de
- https://www.seorankking.de
For more info, check out our complete guide to 301 redirects .
How to Avoid Common Canonization Mistakes
Canonization is a somewhat complex subject. As such, there are many misconceptions about how to properly canonize.
Here are some mistakes many make:
Error 1: Block canonical URLs with the robots.txt
Blocking a URL in the robots.txt file will prevent Google from crawling it, which means Google won’t be able to see canonical tags on that page. This in turn prevents the link equity from being carried over from the non-canonical URL to the canonical URL.
Error 2: Set the canonicalized URL to ‘noindex’
Never mix noindex and rel = canonical. These are contradicting instructions.
Google will normally prioritize the canonical tag over the noindex tag, as John Mueller states here . But it’s still the wrong approach.
If you want to set a URL to “noindex” and canonicalize it, use a 301 redirect. Otherwise use rel = canonical.
Error 3: Setting 4XX HTTP status codes for the canonical URL
Setting a 4XX HTTP status code for a canonical URL has the same effect as using the “noindex” tag. Google won’t see the canonical tag and won’t be able to transfer the link equity to the canonical version.
Error 4: Canonicalization of numbered pages on the root page
Numbered pages should not be canonicalized to the first page in the series. Instead, self-referencing canonicals should be used on all numbered pages.
Why?
As Google’s John Mueller explained on Reddit , this is an incorrect use of the rel = canonical:
“What you should absolutely avoid is the use of rel = canonical on page 2, which points on page 1. Page 2 is not synonymous with Page 1, so the rel = canonical would be wrong. “
You should also use rel = prev / next tags for page numbering. These are no longer used by Google , but still used by Bing .
Error 5: Using hreflang without canonical tags
Hreflang tags are used to set the language and geographic orientation of a web page.
Google says that when using hreflang one should “ specify a canonical page in the same language or the best possible substitute language if a canonical does not exist for the same language” .
How to Find and Fix Canonization Issues
It is easy to make mistakes with canonicalization, so it pays to regularly check your website for canonical tag-related issues and fix them ASAP.
You can use the SEMrush site audit tool for this .
The Site Audit Tool will scan your website for any bugs and up to 100 pages with the free version.
Here are the twelve most common problems the Site Audit Tool can find related to Canonization and how to fix them.
1. Canonical refers to 4XX
This warning is triggered when one or more pages are canonicalized to a 4XX URL.
Why is it a problem?
Search engines don’t index 4XX pages because they don’t work. Hence, they ignore any canonical tags referencing such pages and often index the wrong (non-canonical) version of the page.
How to fix it
Check the affected pages and replace the dead (4XX) canonical links with links to working (200) pages that you want indexed.
2. Canonical refers to 5XX
This warning is triggered when one or more pages are canonicalized to a 5XX URL.
Why is it a problem?
5XX HTTP status codes indicate server problems resulting in an inaccessible canonical page. Google is not very fond of indexing inaccessible pages so they can ignore the canonical.
How to fix it
Replace any broken canonical URLs with valid URLs. Check for server misconfigurations if the specified canonical version appears correct. Note that if the crawl occurred, if your website was down for maintenance, or if your website’s server was overloaded, it can be a temporary problem.
3. Canonical refers to forwarding
This warning is triggered when one or more pages are canonicalized to a redirected URL.
Why is it a problem?
Canonicals should always refer to the most authoritative version of a page. This is not the case with forwarding URLs. As a result, search engines may misinterpret or ignore the canonical.
How to fix it
Replace the canonical links with direct links to the most authoritative version of the page (i.e. one that returns a 200 HTTP status code and does not forward).
4. Duplicate pages without a canonical
This warning is triggered when there are one or more duplicate or very similar pages that do not specify a canonical version.
Why is it a problem?
Since no canonical is given, Google will try to identify the most appropriate version that will appear in the search results. This may not be the version you want indexed.
How to fix it
Check the group of duplicates. Choose a canonical version to be indexed in search results. Include this as the canonical version of all duplicates throughout (and add a self-referencing canonical tag to the canonical version).
5. Hreflang too non-canonical
This warning is triggered when one or more pages specify a non-canonical URL in their hreflang annotations.
Why is it a problem?
Links in hreflang tags should always point to the canonical pages. The reference to a non-canonical version of a page from hreflang annotations can confuse and mislead search engines.
How to fix it
Replace links in the hreflang annotations of the affected pages with their canonical pages.
6. Canonical URL has no inbound internal links
This warning is triggered when one or more canonical URLs have no inbound internal links .
Why is it a problem?
Canonical URLs without internal links are not accessible to website visitors. Somewhere on the website you are instead directed to a non-canonical version of the page.
How to fix it
Replace all internal links to canonical pages with direct links to the canonical page.
7. Non-canonical page in the sitemap
This warning is triggered when one or more non-canonical pages are listed in the sitemap.
Why is it a problem?
Google says you shouldn’t include non-canonical URLs on your sitemap. This is because pages in sitemaps are seen as suggested canonicals. You should only list pages that you want to index in sitemaps.
How to fix it
Remove the non-canonical URLs from your sitemap.
8. Non-canonical side specified as canonical side
This warning is triggered when one or more pages specify a canonical URL that is also canonicalized to another page. This creates a “canonical chain” where side A is canonicalized on side B, which is then canonized on side C.
Why is it a problem?
Canonical chains can confuse and mislead search engines. As a result, the specified canonical can be misinterpreted or ignored.
How to fix it
Replace non-canonical links in the canonical tags with direct links to the canonical page.
Suppose side A is canonicalized on side B, which is then canonized on side C. Replace the canonical link on page A with a link on page C.
9. Open Graph URL does not match canonical
This warning is triggered if there is a mismatch between the specified canonical and the Open Graph URL on one or more pages.
Why is it a problem?
If the Open Graph URL does not match the canonical, a non-canonical version of a page is shared on social networks.
How to fix it
Replace the Open Graph URL on the affected pages with the canonical URL. Make sure the two URLs are the same.
Note : URLs within Open Graph Tags (OG tags for short) must be absolute and use the https: // or https: // protocols, as is the case with canonical tags.
10. Canonical from HTTPS to HTTP
This warning is triggered when one or more secure (HTTPS) pages specify a non-secure (HTTP) version as the canonical page.
Why is it a problem?
HTTPS is a ranking factor , so it makes sense to use secure versions of pages as canonicals whenever possible.
How to fix it
Redirect the HTTP page to the HTTPS page. If that is not possible, add a rel = ”canonical” link from the HTTP version of the page to the HTTPS version.
Note : Google also lists implementing HSTS as a possible solution.
11. Canonical from HTTP to HTTPs
This warning is triggered when one or more non-secure (HTTP) pages specify a secure (HTTPS) version as the canonical page.
Why is it a problem?
HTTPS is preferred over HTTP. Having an HTTP version of a page, which then determines the HTTPS version as canonical, is contradictory.
Note : This probably isn’t causing a major problem, but it’s still worth fixing if possible.
How to fix it
Use a 301 redirect from HTTP to HTTPS. You should also replace any internal links to the HTTP version of the page with the links directly to the HTTPS version.
12. Non-canonical site receives organic traffic
This warning is triggered when one or more non-canonical pages appear in search results and receive organic traffic (which shouldn’t be).
Why is it a problem?
Either your canonical tags are set up incorrectly or Google has chosen to ignore the canonical you specified.
How to fix it
Check whether the rel = canonical tags are correctly set up on all reported pages. If this is not the problem, use the URL checking tool in the Google Search Console to check whether Google really considers the given (canonical) URL to be canonical. If there is a disagreement, you should find the reason for it.
Closing word
Canonical tags aren’t that complicated.
They are difficult to understand at first.
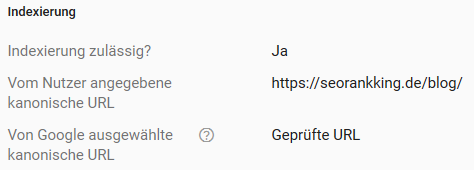
Remember that canonical tags are not a guideline, but a signal to search engines. In other words, search engines may choose a different canonical than the one you selected.
You can use the URL checker tool in Google Search Console to view both the user-specified and Google-selected canonical:
To find and fix possible errors and problems with canonicalization, you can use SEMrush’s site audit tool (also with a free account).





